The World's First Model Built for OpenClaw

Something unusual has been happening on OpenRouter.
Over the past few weeks, traffic to Z.ai’s GLM model family has surged quietly. No promotional campaign. No viral demo. No price cut. Yet the usage curve has bent sharply upward, and the pattern of requests looks nothing like a typical chatbot workload.
The calls are dense with tool invocations. Context windows are stretched long. Sessions persist for minutes, sometimes hours, cycling through dozens of sequential function calls before terminating. To anyone familiar with AI agent architectures, the signature is unmistakable: these are not humans chatting. These are agents working.
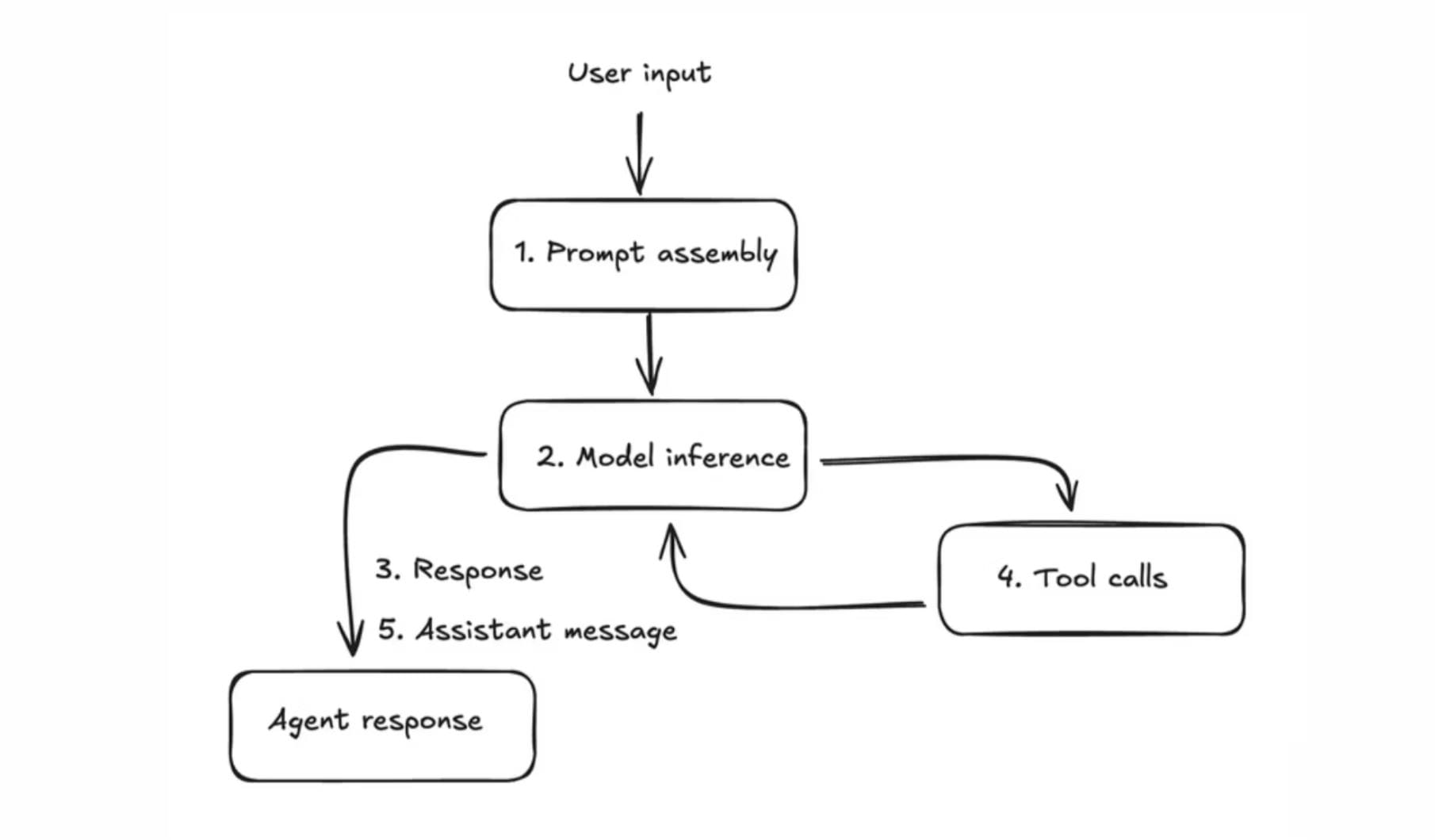
The most likely explanation traces back to a single open-source framework that has quietly become one of the most active agent runtimes in the world: OpenClaw.
On March 16, Z.ai suddenly released a large model specifically designed for OpenClaw: GLM-5-Turbo.
GLM-5-Turbo: A Model With a Job Description
Z.ai, the Beijing-based AI lab behind the GLM model family, is releasing GLM-5-Turbo as the first large language model explicitly built for the OpenClaw agent framework. Not adapted. Not fine-tuned after the fact. Designed from the ground up to function as the brain of a persistent, tool-using, task-executing AI agent.
This matters because every OpenClaw user already knows the pain. General-purpose models, no matter how intelligent, routinely fail at the specific demands of agent workflows. A tool call returns malformed JSON. A multi-step task drifts off course after the fourth instruction. A long-running cron job silently halts at hour two because the model lost track of what it was doing. Intelligence is not the bottleneck. Reliability is.
GLM-5-Turbo is not trying to be the smartest model on the leaderboard. It is trying to be the one that does not break at 3 AM when your agent is halfway through a scheduled pipeline.
What Breaks When Your Agent Never Sleeps
In addition to writing AI Secrets, I run a marketing operation powered almost entirely by an OpenClaw agent. It handles competitor monitoring, social listening, content drafting, campaign performance tracking, and cross-channel distribution — all on automated schedules. Every morning, it pulls data from six or seven sources, synthesizes reports, pushes drafts to our CMS, and delivers briefs to the team’s Slack. On a good day, it replaces three hours of manual work before I finish my coffee.
Most days, it works. Some days, it does not. And the failures are never about intelligence.
The agent will plan a CRM API call with flawless reasoning — correct endpoint, correct payload structure, correct authentication headers — and then hallucinate a parameter name that does not exist. One malformed JSON tool call at 2 AM, and the entire scheduled pipeline dies silently. I wake up to a missing daily brief and a cryptic error buried in a session log. The model knew what to do. It just could not say it in the right format.
Or the model drifts. A typical task chain — pull campaign metrics from the ad platform, cross-reference with CRM conversion data, generate a performance summary, format it as a Notion page, notify the team via webhook — completes steps one through three flawlessly. Then somewhere around step four, the agent forgets the output format I specified. By step five, it is solving a different problem entirely. All the context is still in the window. The model simply stopped paying attention to it.
Then there is the endurance problem. My morning pipeline runs for ten to fifteen minutes of continuous model interaction — dozens of tool calls, hundreds of thousands of tokens. Some models start sharp and degrade halfway through, as if they are getting tired. Tool calls that were precise at minute two become sloppy by minute eight. Instructions followed perfectly in the first sub-task are quietly ignored in the fourth.
These are not hypothetical complaints. They are my Tuesday morning. And they are precisely the failure modes that GLM-5-Turbo was designed to eliminate.
What GLM-5-Turbo Actually Delivers
The model’s capabilities cluster around five areas, each targeting a real failure mode that agent operators encounter daily.
Tool Calling That Does Not Hallucinate
An agent’s value lives or dies in its ability to call external tools correctly. One malformed function call can cascade into a failed task chain, a missed delivery, or worse, a silent error that corrupts downstream data.
General-purpose models treat tool calling as a secondary skill, something bolted onto a conversational core. GLM-5-Turbo treats it as the primary interface. Z.ai’s training pipeline weighted tool-call accuracy and format compliance as first-class objectives, not afterthoughts. The result is a model that generates clean, parseable tool invocations at a rate that meaningfully reduces the “retry and pray” pattern familiar to anyone running agents in production.
Complex Instruction Decomposition
Real agent tasks rarely arrive as single commands. A user says: “Monitor our competitor launches, pull engagement data from three platforms, generate a trend report, format it for the team dashboard, and send a summary to Slack.” Behind that sentence are five sub-tasks, each with dependencies, each requiring a different tool, some of which must run in sequence and others in parallel.
GLM-5-Turbo is optimized for this kind of multi-step decomposition. It parses compound instructions into execution plans, maintains awareness of which sub-tasks have completed, and coordinates handoffs between them. For users running OpenClaw’s multi-agent orchestration, this translates into fewer broken chains and less manual intervention.
Temporal Awareness and Long-Task Persistence
Most models operate in a perpetual present. They process the current context window and generate a response. They have no native concept of “come back in thirty minutes” or “continue what you started two hours ago.”
Agent frameworks like OpenClaw demand exactly this. Scheduled tasks, heartbeat checks, cron-driven workflows — all require a model that understands time as a dimension of its instructions, not just a metadata field. GLM-5-Turbo was trained with temporal reasoning as an explicit capability: understanding deadlines, sequencing time-dependent actions, and maintaining execution coherence across extended sessions that would cause general models to drift or stall.
From Vibe Coding to Agentic Engineering
The coding abilities of frontier models have received enormous attention. Most of it focuses on what might be called “vibe coding” — generating functions from natural language, autocompleting snippets, explaining code. Useful, but shallow.
Agent-native coding requires something deeper: the ability to plan a multi-file change, execute it across tools, test the result, debug failures, and iterate — all without a human in the loop. This is not code generation. It is software engineering conducted by an autonomous system.
GLM-5-Turbo pushes into this territory. Its training included extended coding trajectories — full sequences of plan, implement, test, fix — rather than isolated prompt-to-code pairs. The model is designed to operate as an engineering agent, not a code suggestion engine.
Throughput for Chain-Heavy Workloads
A single user request to an OpenClaw agent might trigger thirty or forty model calls: parsing the task, calling tools, processing results, deciding next steps, formatting output, delivering to a channel. Multiply that across scheduled tasks running for multiple users, and the model’s inference speed and throughput become as important as its intelligence.
GLM-5-Turbo is optimized for this pattern. High token throughput, low latency on sequential calls, and stable response times under sustained load. For agent operators, this is the difference between a workflow that completes in two minutes and one that takes fifteen.
The Bigger Shift: Models Built for Frameworks
Step back from the spec sheet, and GLM-5-Turbo represents something more significant than a single product launch.
For years, the relationship between models and frameworks flowed in one direction. Frameworks adapted to models. LangChain wrapped its abstractions around GPT’s API conventions. AutoGen designed its agent loops to accommodate Claude’s context limits. OpenClaw built compatibility layers for whatever models were available. The model was the sun; everything else orbited around it.
GLM-5-Turbo reverses that gravity.
Here, the framework is the fixed point, and the model has been shaped to serve it. Z.ai looked at how OpenClaw agents actually work — the tool-call patterns, the task structures, the failure modes — and built a model that fits those requirements natively. The framework did not adapt to the model. The model adapted to the framework.
This is the same pattern that transformed other technology stacks. NVIDIA did not wait for developers to write code that happened to run well on GPUs. It designed CUDA and then shaped its hardware to make that programming model fly. The platform became the specification, and the silicon followed.
If OpenClaw and frameworks like it become the operating system layer for AI agents, then “agent-native” may become a model category in its own right — alongside “chat-optimized” and “code-specialized.” Z.ai is the first to stake that claim explicitly. It is unlikely to be the last.
Why Z.ai, and Why Now
The release of GLM-5-Turbo marks a quiet but meaningful inflection point.
For the past three years, the AI industry has measured progress in intelligence: bigger models, higher benchmarks, more capabilities. That race continues, but a parallel race has now begun — one measured not in intelligence but in reliability.
An agent does not need to be brilliant. It needs to show up every day, execute its tasks correctly, and not break when the workload gets heavy. It needs a model that treats tool calls as seriously as prose, that understands time as a working dimension, and that can sustain coherence across hours of autonomous operation.
GLM-5-Turbo is the first model built around that premise. It will not be the last.
If this model becomes the default "brain" of the world's fastest-growing intelligent agent framework, Z.ai will gain widespread recognition that no benchmark score can match.
The age of agent-native models has begun. And the first question it asks is not “how smart is your AI” but something far more practical: does it still work at 3 AM?