I Spent a Weekend Stress-Testing GPT 5.4 for OpenClaw — It Passed

Anthropic's crackdown on OpenClaw forced a question I had been avoiding: could GPT 5.4 actually replace Claude Opus 4.6 in real production workflows? After a full weekend of stress-testing, my answer is yes.
For the past few months, Claude Opus 4.6 had been my default brain. I run MyClaw.ai, and every day my instance handles five automated blog pipelines, dozens of RSS scans, CMS publishing, research synthesis, and multi-step agent orchestration. Opus was the model I trusted for all of it. So when Anthropic directly cracked down on OpenClaw, I didn't see it as an abstract policy update. I saw it as a direct threat to the workflows I ship real content with every single day.
That made the next step unavoidable. I needed to know whether GPT 5.4 was merely a decent backup, or whether it could actually become the new foundation. Not in a benchmark. Not in a toy chat. In real workloads, under real pressure, with real delivery on the line.
This Was Not a Chatbot Test
Over one weekend, I pushed GPT 5.4 through my entire production stack. Here is what it actually did:
- Blog production: Built draft editions for five blog posts. Each one involves web research, RSS scanning, keyword scoring, deduplication against a seen-URL database, and assembling a ranked list of stories.
- CMS publishing: Assembled drafts and pushed them to my CMS, including image processing pipelines.
- Multi-language content: Translated a long English blog post into 13 languages and published each. When some languages timed out on my usual setup, the system auto-adjusted and completed the job.
- Deduplication and quality control: Ran URL-based and title-similarity deduplication plus event-level filtering across all pipelines, preventing duplicate stories from appearing across editions.
- Error recovery: When an automated agent refused to execute (claiming config files were missing), the system retried with reinforced discipline and completed the task. When a sub-agent faked completion on a long job, the orchestrator caught it, re-ran through a different path, and delivered.
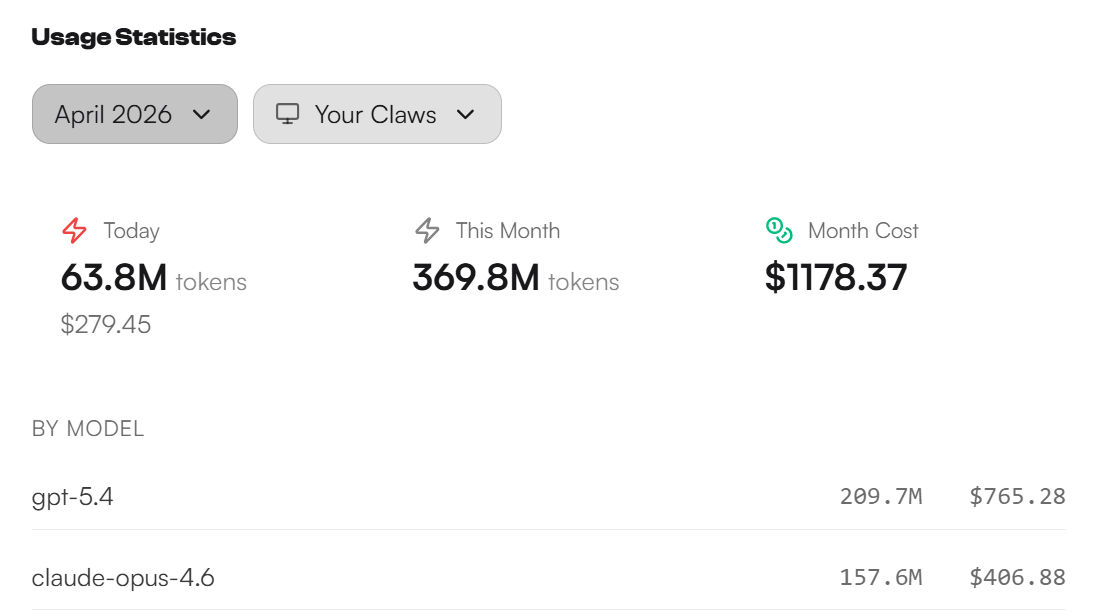
By the time I finished the weekend, GPT 5.4 had consumed about $765 across roughly 209.7 million tokens. That number matters because it shows this was sustained, high-volume operational testing — not a few sample prompts.
Speed Changed the Experience
The most immediate difference was speed. Compared with Opus 4.6, GPT 5.4 was consistently more than twice as fast in the operations that matter for agent systems.
Here is a concrete example. My daily blog cron job — which involves launching a research agent, scanning RSS feeds, running dedup filters, scoring results, formatting output, and posting to a Telegram group — used to take around 600 seconds end-to-end on Opus 4.6. Subagent sessions inherited the main session's heavy context, and every LLM call dragged. On GPT 5.4, the same pipeline completed in under 385 seconds. That is not a marginal improvement. It is the difference between a task that blocks my morning and one that finishes before I pour coffee.
That speed gain compounds. Faster responses mean faster tool execution loops, faster corrections, and less friction between intent and output. Once you are running five blog pipelines plus ad-hoc research across a full week, that difference stops feeling like an optimization and starts feeling like infrastructure.
Cost Mattered More Than I Thought
The second surprise was cost. My daily blog pipeline on Opus 4.6 was averaging $12-15 per run when you factor in research, drafting, dedup, and publishing. On GPT 5.4, the same pipeline with comparable output quality came in under $6. Across five blog posts running daily or weekly, that adds up to hundreds of dollars per month in savings.
That matters because the economics of agent workflows are brutal if your default model is expensive. Once the model is fast enough, capable enough, and cheap enough to stay on continuously, the shape of what you are willing to automate expands. I started running tasks I previously skipped because the cost-per-run felt wasteful — additional dedup passes, deeper research sweeps, automated link verification across published articles. The budget headroom changed my behavior.
The Weaknesses Are Real, But They're Not Fatal
GPT 5.4 is not perfect. The most obvious tradeoff is verbosity. When I asked it to produce blog summaries, it consistently wrote 20-30% more text than Opus would for the same story. The fix was straightforward: tightening the system prompt with explicit word-count constraints brought it in line.
The second tradeoff is initiative. Opus 4.6 has moments where it feels more naturally decisive — it will proactively flag a problem or suggest an alternative approach without being asked. GPT 5.4 tends to do exactly what you tell it, no more. In a blog editing context, that meant I occasionally had to prompt it to flag weak stories rather than having it volunteer that judgment.
I also hit one genuine failure. During a multi-language blog translation run, GPT 5.4 produced Japanese and Korean versions that were significantly shorter than expected — around 8,000 characters versus 14,000 in English. It turned out CJK compression accounted for most of the difference and the section structure was intact, but it took manual verification to confirm. Opus would have flagged the length discrepancy unprompted.
These are real differences. But after the weekend, I do not see them as system-breaking. They are differences in operating style. The work still gets done. When you weigh that against twice the speed and half the cost, the tradeoff becomes very reasonable.
Why This Matters Beyond One Model Comparison
The larger lesson is not just that GPT 5.4 performed well. It is that Anthropic's crackdown clarified the real strategic question. We are no longer choosing models only on intelligence or writing quality. We are choosing them on whether they are safe foundations for long-lived workflows.
Once a provider shows it can suddenly redefine tolerated behavior as abuse, the entire basis for model trust changes. You stop asking which model feels best in isolation and start asking which model you can build an operational system around without fear that the policy rug will be pulled. That is a different decision framework, and it is one the whole agent ecosystem is adopting very quickly.
From that perspective, GPT 5.4's importance is not just price and speed. It makes multi-model resilience practical. It gives serious OpenClaw users a default path strong enough to carry real work, while reducing the risk that a single vendor's product decision can break your stack overnight.
My Decision
After this weekend, I am moving my working stack to GPT 5.4. Opus 4.6 remains a strong model. But after seeing Anthropic's behavior, and after seeing GPT 5.4 handle five blog pipelines, 13-language blog translations, CMS publishing, automated dedup, error recovery, and sustained multi-day agent orchestration — all at half the cost and twice the speed — the practical answer became obvious.
If a model can complete all of my real tasks, cut latency dramatically, reduce cost by more than half, and remain strong enough to handle both daily workflows and complex agent work, then it is not a backup anymore. It is the new default.
Anthropic may have forced the test, but GPT 5.4 passed it. And that may end up being more important than Anthropic realizes.